




ai软件第一种asSpecification工作截图#轨迹对比的调试方法(组图)
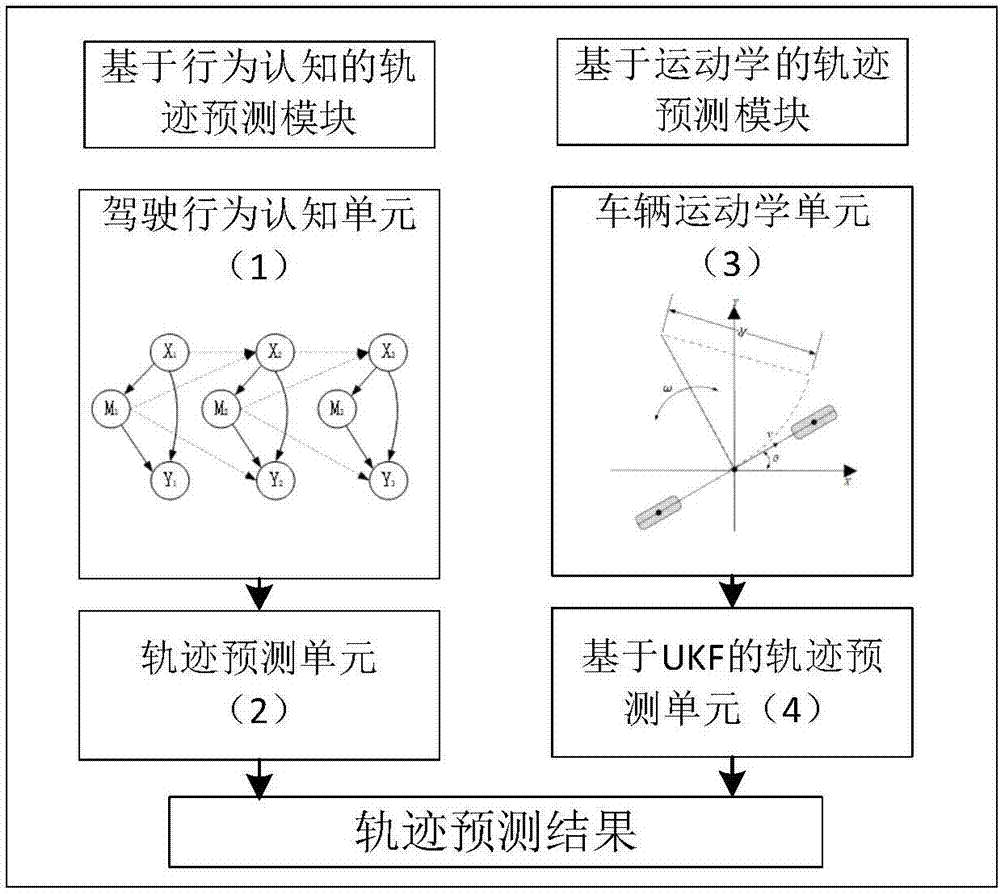
 UI设计师
UI设计师第一种借助程序员跟程序的交互收集程序员的安装行为来完成定位推荐。我们让程序员在轨迹上做反馈,希望用尽可能少的反馈,推荐出最早的出错步骤,这个推荐的过程具有鼓励性和解释性,在程序员定位到的那一刻,整个在轨迹上的交互过程能帮助理解和预测出错误的理由。
这是我们设计的软件截图,轨迹在上面以可视化的形式进行展开,程序员在后面可以给出反馈。工具按照反馈作出推荐并学习反馈提升推荐效率。每次推荐也辅之以推荐理由。
FeedbackasSpecification工作截图
#轨迹对比的调试方式
第二种方式是把程序的执行认为是一种特殊的参照,来定位和解释根因。
这个方式的应用场景是回归错误(RegressionBug)[3]。对一个回归错误,我们有一个错误的版本和(过去)正确的版本,以及一个能够借助的测试用例。我们对比两个版本的执行轨迹,来生成调试过程。
在下图中,我们可以在软件中发现可视化的轨迹,左边是错误的轨迹,然后右边是恰当执行的轨迹。
我们手动匹配两条轨迹,来受到两个版本的执行差异(例如,相同时刻是否读取和写入了不同的变量,哪一方法没有被执行等信息)。
我们使用轨迹匹配关系来支持程序员在软件中探讨和理解缺陷。我们会高亮每个匹配的流程所对应的源代码。我们的软件可以推荐一个全手动化的调试过程;也可以辅助完成交互式调试过程,即,让程序员交互式地预测和构建特定方法来理解代码(例如客户在下方可以直接反馈这个方法到底是否需要被执行,是否读取了一些错误的变量)。
ProgramExecutionasSpecification工作截图
利用轨迹匹配关系,工具可以完成双边切片,在两侧轨迹上同时做切片,可以提问以下问题:
在过去的版本当中某个(恰当)函数何时赋值?
目前这个版本当中某个(出错)函数何时赋值?
为何(在正确版本中)本该执行的方法在现有版本中没有执行?
为何(在正确版本中)不该执行的流程在现有版本中执行?
Videodemo1(90秒):
Videodemo2(20秒):
这个视频展现了我们工具的调试过程模拟能力。根据轨迹对比,我们手动生成程序员在轨迹上的观察和调试过程。
#技术原理#
#TraceAlignment的挑战
这个工作中,我们假定存在一种完美的代码匹配模式。在轨迹匹配上,我们必须解决一些挑战:
挑战1:效率问题
一条轨迹可以被视为一连串步骤,如果我们使用经典的数组串匹配算法,一条轨迹是宽度是m,另外一条轨迹长度是n,那它的复杂度就是O(mn)。一般的轨迹长度约为100万步。一般的单机就无法支持实际匹配效率。
挑战2:匹配选择
程序的执行中会有众多循环迭代。每次迭代都会执行完全同样的指令,我们怎么匹配那些指令的执行?
挑战3:版本变更
最终,两个版本的代码存在代码更改引起的差别。这些更改也许会颠覆控制流。然而,代码层面上控制流的差异有之后并不会妨碍匹配逻辑。比如说当一个while循环被设置为一个if条件判定,第一次的循环执行可以跟这个if条件判定的执行所配上,我们在算法上怎么兼容这些状况?
#TraceAlignment的性质
在这个工作中,我们强调轨迹匹配的复杂度是线性的,这意味着轨迹匹配原来可以比字符串匹配“便宜”的多。这得益于程序的结构信息可以帮助我们剪枝大量搜索空间,提高运行精度。这里,我们强调了三个轨迹匹配性质,来加速匹配过程。
此处,我们强调了三个轨迹匹配性质,来加速匹配过程。
迭代执行的原子性
IterationBoundaryPreserving(IBP)Property
程序执行的之后会造成这些迭代,而每一次循环执行所造成的降维具有匹配上的原子性。因此,我们可以按照循环把轨迹分段,迭代段中的流程不能跨段匹配。
迭代执行的匹配时序性
Iterationorderpreserving(IOP)property
一个循环可以形成这些迭代段,我们强调,段和段的匹配只能根据排序。具体机理参加我们论文的证明。
基于先前的两个性质,我们可以把两条轨迹转化成两棵树。树后面每一个父节点表示一个迭代段,每个叶节点代表一个方法。通过这个树的方式,我们可以自顶向下进行匹配,显然这个算法是线性的。
首次迭代匹配的宽松性Firstiterationrelaxation(FIP)property
修改会改变控制流语义。这个性质中,我们定义哪些样的控制流设置并不会妨碍匹配语义。这里,我们调整了树的构造方式来兼容这些状况。具体细节请参看我们的论文。
#轨迹匹配的分类
当两条轨迹的匹配关系被确认,那我们就可以分类出如下匹配关系:
执行不变(Identical):如果错误轨迹上的一步可以跟正确轨迹上的一步配出来,并且他们拥有同样的读写变量,我们觉得它是一个恰当的方法。
变量变化(Data-different):如果错误轨迹上的一步可以跟正确轨迹上的一步配出来ai软件,但是他们读了不同的变量,那我们觉得它的数据流形成了错误,此时就可以在双边做切片,去追溯这个正确和出错变量的来源。
执行流变化(Control-different):如果错误轨迹上的一个方法,它不涉及代码更改,却没有方法配到恰当轨迹上的任何一步,那我们觉得它的控制流出错了,那此时借助控制流的切片以及其它一些方法的剖析,去认识为什么这一步不需要出现。
代码变化(Codedifferent):执行的代码出现了变化。
由此,我们从轨迹上的最后报错开始,不断在两条轨迹上做双边切片,生成调试过程,并成为解释。
#实验和结果
在实验中,我们收集了24个现实中的回归错误。实验结果证实我们的科技在查准和查全上具备优势。
更重要的是,相比于特色切片,我们的解释带有很高的简单性。
总结:我们借助生成那样的调试模式,并辅助以交互式软件设计,让程序员更好的去学习、理解和预测代码。一旦它们无法理解此中原理,如果定位和恢复,是程序员自己见仁见智的决定。
#从程序执行到模型训练#
程序执行在传统工具当中虽然是相当重要的方式,有之后我们称之为record&replydebugging。在下一个工作中,我们把相同的观念采用在建模训练上,来帮助数据科学家及其程序员们理解模型练习过程。从人工智能的角度上,我们也拓展了基于过程的可解释AI这一领域。
#可解释AI领域工作的梳理
现在的可解释AI工作可以分类为下列两类。
attributionproblem
这类工作以便探讨一个样本的什么部分对最终的分析影响最大。典型的工作包括integralgradient和gradcam。
influencefunctionproblem
这类工作以便找到对某个分析结果影响最大的训练样本。
#From"What"to"How"
而我们期望了解模型(或者其分析能力)是借助多次迭代训练造成的,比如我们在调试模型中期望能提问以下问题:
针对高维空间中的分类边界和高维表示,他们是怎样真正产生的?
这些样本相比于其它样本,被模型学习较为困难的理由?
模型在练习过程中是怎样抉择学习样本的?
......
#DeepVisualInsight(DVI)工具
基于这种看法,我们强调了Time-travellingVisualization框架,支持深度神经网络分类器的可视化。我们期望把在高维上出现的事情在低维上可视化展现,以便让人进一步的理解和预测。
以下图为例,每一种形状对应一种分类,每一块区域对应高维空间上的一个分类区域,每一个点对应一个样本,点的底色代表这个样本的标签,这个点的所在区域就代表模型把这个点分析成了类。比如,一个红色的点且在一个蓝色区域里,可以代表一张照片狗被猜测成了狗这一个分类;而一个黑色点在一个白色区域旁边,可能是一架飞机被分析成了一个狗。
给定一个建模,我们把它的高维分类边界可视化在画布上。这样我们能够了解,每个样本离分类边界有多远,样本与样本之间有多近,等信息。
更进一步,我们可以记录模型练习过程中的各类“快照”。每个快照可以得到一副画布,通过组合画布,我们能够受到锻炼过程的一个动画。
在这个动画上他们可以从概念上去理解,在整个高维空间上分类边界是如何样被塑造和颠覆的。而它的点可以觉得是在高维的embedding,它是如何被学到的,点和点之间的邻居关系是如何产生的?
#示例说明
此处,我以模型的对抗训练为例来表明这个工具所能提供的帮助。给定一个建模,我们对这个模型形成对抗样本。为了提高模型的鲁棒性,我们可以把这种对抗样本喂到模型里再次训练。
我们可以看见在以前测试集上这个建模表现良好,测试精确率能超过92%;然而对生成的对抗样本来说,它的分析精确率只有50%。
Accuracy
AdversarialSamples
51.3%
TestingSamples
92.3%
在得到对抗样本以后,在对抗训练之前,我们可以看见下图所示的可视化效果。这个蓝色的点是一个检测样本,它被建模正确分析。我们可以看见蓝色点落在白色的区域里,同时有10个相邻的对抗样本为红色,表示他们都猜测错了。
在做第一轮对抗训练的之后,我们在下图上看到这个黄色点被挪走了。这是由于模型为了分析他周边的一些对抗样本邻居,需要把他们放在其它区域。通俗而言,红色的点被“带跑”了。
我们看指标,发现对抗样本的确切率确实增加了,但检测样本的确切率甚至增加了。这个现象在后续训练中会不断变得显著。
最终我们会看到就是不止这几个点,有众多的对抗样本点都被拉回了自己的区域,但他们被拉回自己区域的时侯,他们附近的锻炼样本,也跟随被“带跑”了。
Accuracy
AdversarialSamples
67.8%(提升16.5%)
TestingSamples
90.3%(降低2.0%)
通过这个现象,我们可以受到一些反思。
包括说要使用对抗样本以及对抗学习这种的科技,现有模型的表示能力是不是太弱了?模型在考量不相同本时,会做哪些样的抉择?以及说我们为了鲁棒性,应该要牺牲很大的恰当性?
可视化本身其实难以回答那些问题,但是可视化的含义在于把这个现象展示出来,引发他们更多的探讨。
后来另外一个现象是,当我们把整个可视化的过程记录下来以后,我们会看到脏数据的移动和正常数据移动虽然也很不一样。对于正常数据即橘红色的点来说,他在第一和第二个epoch中就早已学得差不多了。而针对这些红色的点即脏数据的点,一般都十分“顽固”,最后是被模型试图拉回Label所指定的区域。所以这种现象也可以辅助我们去预测。
#DVITool:ATensorboardPlugin#
我们基于Tensorboard框架完成了我们的软件。我们的工具还包括了怎样帮助客户理解、查询、分析、高亮一些点,比如可以让客户看一些详细的照片,具体的举例等。
#可视化模型技术实现
##假设
我们假定,一个分类模型必须有两部份构成。一个别是表征学习,即,一个样本会被转换成一个表征;一个别是表征拟合,即,学习的表征学习被进一步拟合到一个特定的分类。
针对图像辨识来说,前端的表征学习可以是前馈层,然后卷完以后会输出一个gap向量被进一步分析分类。对于自然语言处理来说ai软件,那前端有也许是用transformer,然后上面接个fitter,去分析分类。
##概述
我们的可视化模型分两部分。
第一个个别是降维的过程,给一个高维的表征,我们期望把它从高维降到低维,由此我们可以确认每个样本在画布上的位置。
第二个个别是升维的过程,这个升维过程是期望把任意一个坐标返回到高维,如果都能往高维投射的话,任意一个点都会投射成一个表征,这个表征就可以喂给fitter去做一次分析。有了这种的过程期间,就可以对画布上的每个像素点进行染色。
##空间&时间性质
这两步实现以后,我们能够完成从高到低进行降维,从低到高维去画背景。从高维到低维,一定会有信息丢失;从低维到高维,也必须有信息增强。由此,我们定义了时间上和空间上的性质,让模型学习的之后才能了解这些信息必须优先保留和提高。
NeighborPreserving:高维的邻居在低维也需要是邻居,即邻居保持属性。
BoundaryDistancePreserving:在高维上距离相当近的边界上的邻居,也无法在低维上被保持。
InverseProjectionPreserving:一个点从高维到低维,再从低维重新增强到高维的过程中,要使信息丢失率最小。
TemporalContinuity:由于历史上的建模训练快照会被记录,要使相邻两个快照的可视化结果是相同的(该性质考虑下去以后,用户看上去常常非常的方便)。
在实践层面上,我们用一个auto-encoder来谋求升维和降维能力。auto-encoder的编码的个别就是迭代的过程,而它的解码的部分就是升维的过程,我们会为每一个classifier学习一个auto-encoder。在训练auto-encoder时,我们把以上的性质转换为训练的代价函数。
#实验和结果
此处是我们实验的结果,在今天所述的4个属性上,整体效果非常好。相比于先前的迭代技术,我们在强度和具体率上有较大的提高。同时,也是第一款生成动画的技术。
#总结#
在这个报告中,我解读了我们基于轨迹的代码调试和建模调试技术。基本的观念都是记录程序执行以及模型练习的轨迹,在轨迹收集之上我们做了更多的预测来支持程序员和数据科学家来观察、理解和预测目标程序和建模。
针对程序分析技术,我们期望把两个轨迹对比出来,这样我们可以在某些程度上生成调试的过程,生成定位的解释,这样可以非常有效的辅助程序员学习这个代码,并且帮助他定位。通俗而言:错误定位可能是程序员见仁见智的决定,但是是否能帮助程序员更好地理解代码必须是将来代码调试器要做更重要的事。
针对可视化分析,我们期望把高维上出现的事件,以直观的形式呈现在数据科学家和程序员之前。由此,帮助人们进一步观察和预测各种锻炼时的现象。

转载原创文章请注明,转载自设计培训_平面设计_品牌设计_美工学习_视觉设计_小白UI设计师,原文地址:http://zfbbb.com/?id=6514
