




人类视觉系统深度学习也称为深度结构学习(DeepLearning)的研究
 UI设计师
UI设计师课程链接:
大V吴恩达曾经说过:做AI研究如同造地球飞船,除了充足的燃料之外,强劲的引擎也有必不可少的。假如燃料不足,则飞船就能够开启预定轨道。而引擎不够出色,飞船或者不能升空。类比于AI,深度学习建模就似乎引擎,海量的训练数据就似乎燃料,这二者对于AI而言同样缺一不可。
深度学习是一个近几年受到关注的探究领域,在机器学习中起着重要的作用。深度学习通过制定、模拟人脑的分层结构来推动对外部输入的数据进行从低级到初级的特点提取,从而无法解释内部数据。
深度学习
深度学习(DeepLearning)的概念始于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。
深度学习也称为深度结构学习【DeepStructuredLearning】、层次学习【HierarchicalLearning】或者是深度机器学习【DeepMachineLearning】)是一类算法集合,是机器学习的一个分支。它尝试为数据的高层次摘要进行模型。
机器学习通过算法,让机器可以从外界输入的长期的数据中学习到规律,从而进行甄别判断。机器学习的演进历程了浅层学习和深度学习两次浪潮。深度学习可以理解为神经网络的发展,神经网络是对人脑或物理神经网络基本特点进行抽象和模型,可以从外界环境中学习,并以与物理类似的交互模式适应环境。神经网络是智能学科的重要部分,为缓解复杂难题和智能控制提供了有效的方式。神经网络曾一度作为机器学习领域受到关注的方向。
我们用一个简单的事例来表明,假设你有两组神经元,一个是接受输入的信号,一个是发送输出的信号。当输入层接收到输入信号的之后,它将输入层做一个简单的修改并释放给下一层。在一个深度网络中,输入层与输出层之间可以有众多的层(这种层并不是由神经元构成的,但是它可以以神经元的方法理解),允许算法使用多个处理层,并可以对这种层的结果进行线性和非线性的转化。
深度学习的由来
1、人脑视觉机理启示
人类每时每刻都遭受着长期的认知数据,但头脑总能很易于地捕获重要的信息。人工智能的核心难题就是模仿大脑某些高效准确地表示信息的能力。通过近些年的探究,我们对大脑机制已有了一些知道,这些都实现了人工智能的发展。
神经学探究表明,人的视觉系统的信息处理是分级的,从低级的V1区提取边缘特性,到V2区的形状,再到更高层。人类大脑在接收到内部信号时,不是直接对数据进行处理,而是借助一个多层的网络建模来获得数据的规律。这种层次
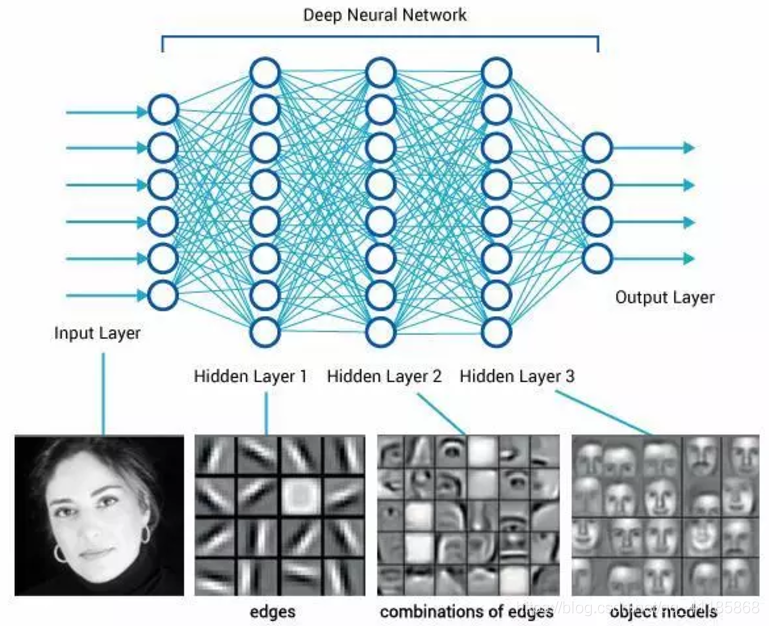
结构的认知系统使视觉系统必须处理的数据量大大降低,并保留了物体有用的结构信息。
2、现有机器学习的局限性
深度学习与浅层学习相对。现在好多的学习方式都是浅层结构算法,它们存在一定的局限性,比如在样本有限的状况下表示复杂变量的能力有限,针对复杂的分类问题其弱化能力得到一定影响。
而深度学习可借助学习一种深层非线性网络构架,实现复杂变量逼近,表征输入数据分布式表示,并且能在样本集很少的状况下来学习数据集的本质特性。
然而浅层学习的应用也很广泛,但它只对简单的计算才有效,并不能到达人脑的反应效果,这就必须深度的机器学习。这些都说明浅层学习网络有巨大的局限性,激发了我们对深度网络模型的研究。
深度机器学习是数据分布式表示的必定结果。有众多学习结构的学习算法得到的学习器是局部估计算子,例如,由核技巧构造的学习器,是由对模板的匹配度加权构成的。对于这种的弊端,通常我们有合理的假定,但当目标变量十分复杂时,由于必须借助参数进行表述的区域数量也有很大的,因此这样的模型泛化能力很差。在机器学习和神经网络研究中分布式表示可以处理维数灾难和局部泛化限制。分布式表示虽然可以较好地表述概念间的相同性,而且适合的分布式表示在有限的数据下能表现出更好的弱化性能。理解和处理接收到的信息是人类感知活动的重要环节,由于这种信息的结构通常都很复杂,因此构造
深度的学习机器去推动一些人类的思维活动是很有必要的。
3、特征提取的应该
机器学习通过算法,让机器可以从外界输入的长期数据中学习到规律,从而进行甄别判断。机器学习在解决图像辨识、语音辨别、自然语言理解等弊端时的大概步骤如图1所示。
首先借助传感器来获取数据,然后经过预处理、特征提取、特征选取,再到推理、预测和辨识。良好的特点表达影响着最后算法的确切性,而且平台主要的计算和检测工作都在这一环节。这个环节一般都是人工完成的,靠人工提取特征是一种特别费力的方式,不能确保选取的品质,而且它的调节需要长期的时间。然而深度学习能自动地学习一些特点,不应该人参与特征的选择过程。
深度学习是一个多层次的学习,如图2所示,用较少的隐含层是不可能超过与人脑类似的效果的。这应该多层的学习,逐层学习并把学习的知识传递给下一层,通过这些方法,就可以推动对输入信息进行分级表达。深度学的实质就是借助完善、模拟人脑的分层结构,对外部输入的声音、图像、文本等数据进行从低级到初级的特点提取,从而无法解释内部数据。与传统学习结构相比,深度学习更注重调模型结构的深度,通常带有多层的隐层节点,而且在深度学习中,特征学习至关重要,通过特征的逐层变换完成最终的分析和识别。
深度学习的经典算法
深度学习成为机器学习的一个分支,其学习方式可以分为监督学习和无监督学习。两种方式都带有其新颖的学习建模:多层感知机、卷积神经网络等属于监督学习;深度置信网、自动编码器、去噪自动编码器、稀疏编码等属于无监督学习。
1、监督学习:卷积神经网络CNNs
20世纪60年代,Hubel和Wiesel通过对猫视觉皮层细胞的探究,提出了展现野(receptivefield)的概念。受此启发,Fukushima提出神经感知机(neocognitron)可看作是CNNs卷积神经网络的第一个实现网络,也是展现野概念在人工神经网络领域的首次应用。随后LeCun等人设计并采取基于差值梯度的算法训练了递归神经网络,并且其在一些方式识别任务中展示出了相对于后来其他方式的领先性能。现代生理学关于视觉系统的理解也与CNNs中的图像处理过程相一致,这为CNNs在图像识别中的应用奠定了基础。CNNs是第一个真正成功地运用多层层次结构网络的具备鲁棒性的深度学习方式,通过研究数据在空间上的关联性,来降低训练参数的总量。目前来看,在图像识别领域,CNNs已经变成一种高效的识别方式。
CNNs是一个多层的神经网络,如图3所示,每层由多个二维平面构成,每个平面又由多个独立的神经元构成。上一层中的一组局部单元作为下一层邻近单元的输入,这种局部连接观点最早起源于感知器。外界输入的图像通过可训练的混频器加偏压进行异或,卷积后在C1层会形成3个特点映射图;但是特征映射图中每组像素分别进行求和加前馈,再通过Sigmoid函数得到S2层的特点映射图;这种映射图再借助滤波器得到C3层;C3与S2类似,再产生S4;最终,这些像素值被光栅化,并且连结成向量输入到神经网络,从而便受到了输出。一般地,C层为特点提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部特点,根据局部特性来确认它与其它特性空间的位置关系;S层是特性映射层,特征映射带有位移不变性,每个特征映射为一个平面,平面上所有神经元的阈值是相同的,因而降低了网络自由参数的个数,降低了网络参数选择的复杂度。每一个特点提取层(C层)就会跟着一个用于求局部平均及二次提取的计算层(S层)人类视觉系统,这便组成了两次特征提取的结构,从而在对输入样本识别时,网络有很高的畸变容忍能力。对于每一个神经元,都定义了对应的接受域,其只接受从自己接受域传来的信号。多个映射层组合出来可以获取层之间的关系和空域上的信息,从而便于进行图像处理。
CNNs是人工神经网络的一种,其适应性强,善于挖掘数据局部特点。它的权值共享网络构架使之更类似于生物神经网络,降低了网络建模的复杂度人类视觉系统,减少了阈值的总量,使得CNNs在机制识别中的各个领域受到应用并获得了很高的结果。CNNs通过结合局部感知区域、共享权重、空间或时间上的降采样来充分运用数据本身包括的局部性等特点,优化网络构架,并且确保一定程度上的位移的不变性。由LeCun出的LeNet模型在应用到各类不同的图像识别任务时都获得了不错的效果,被觉得是通用图像辨识平台的代表之一。通过这种年的研究工作,CNNs的应用越来越多,如人脸检测、文档分析、语音检测、车牌辨识等方面。2006年Kussul等人强调的辅以排列编码技术的神经网络在指纹识别、手写数字识别和小物体识别等识别任务上都获得了与一些专用分类系统非常的性能体现;但是在2012年,研究人员把视频数据里连续的帧只是卷积神经网络的输入数据,这样就可以引入时间维度上的数据,从而识别人体的动作。
2、无监督学习:深度置信网DBNs
DBNs是现在研究和应用都非常广泛的深度学习结构,它由多个受限玻尔兹曼机累加而成。RBM结构如图4所示,分为可视层即输入数据层(υ)和隐藏层(h),每一层的结点之间没有连结,但层和层之间互相互连。相比传统的sigmoid信念网络,RBM易于连结权值的学习。Hinton等人认为,如果一个典型的DBN有l个隐含层,那么可以用联合概率分布来表述输入数据υ和隐含向量的关系:
其中,是条件概率分布。DBN学习的过程中,所要学习的就是联合概率分布,在机器学习的领域中,联合概率分布的含义就是对象的生成。
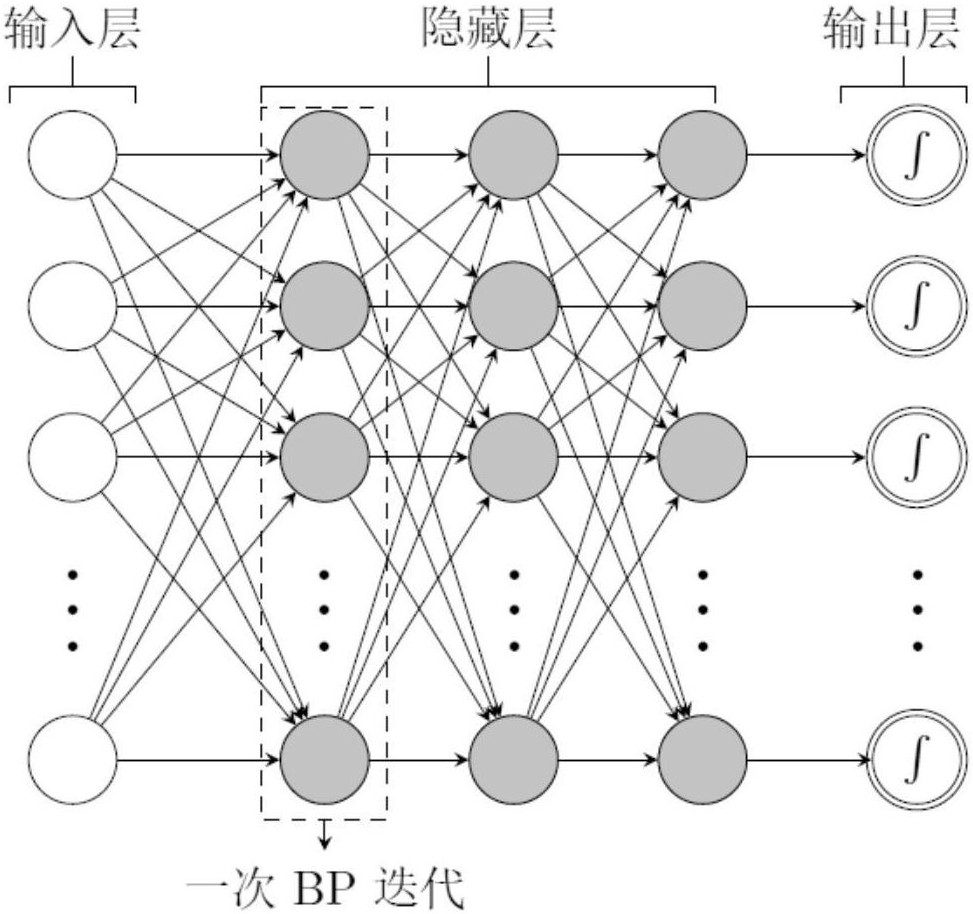
传统的BP算法在经典的网络结构中广泛应用,但针对深度学习的练习却遭遇了这些困难:第一,BP算法是监督学习,训练必须有标签的样本集,但实际能受到的数据都是无标签的;第二,BP算法在多隐层的学习结构中,学习过程较慢;第三,不适度的参数选择会造成局部最优解。为了获得生成性权值,预训练运用非监督贪婪逐层算法,非监督贪婪逐层训练算法被Hinton证明是有效的。
非监督贪婪逐层训练算法的核心观念是:把DBN分层(见图5),每一层进行无监督学习,每次只练习一层,将其结果成为高一层的输入,最后用监督学习调整所有层。在这个训练阶段,首先,在可视层会造成一个向量v,通过它将值映射给隐单元;但是,可视层的输入会被随机地选取,以尝试去构建原始的输入信号;最终,这些新可视单元重新映射给隐单元,获得新的隐单元h。执行这些反复方法叫做吉布斯(Gibbs)采样。隐层激活单元和可视层输入之间的相关性差异就成为权值更新的主要根据。在最高两层,权值被联结到一起,从而更低层的输出将会提供一个参考的线索以及关联给顶层,这样顶层就会将其联系到它的记忆内容。预训练结束后,DBN可以运用带标签的数据及BP算法去微调网络构架的功耗。DBNs的BP算法只应该对差值参数空间进行一个局部的搜索,这相比前向神经网络来说,训练的时间会明显下降,训练RBM是Gibbs有效的随机抽样技术。在贪婪的学习算法过程中,采用了Wake-Sleep算法的基本思想,算法在Wake阶段,利用学习受到的指数,按照自底向下的顺序为下一层的训练提供数据;在Sleep阶段,按照自顶向上的排序利用指数对数据进行重组。
DBNs是现在研究和应用都非常广泛的深度学习结构,由于灵活性很高,因此非常易于拓展,例如卷积DBNs就是DBNs的一个拓展,给语音信号处理难题带来了突破性的进展。DBNs作为一个新兴的生成模型,已广泛应用到了对象模型、特征提取、识别等领域。
深度学习的应用
在实际应用中,很多难题都可以借助深度学习解决。那么,我们举一些实例:
黑白图像的着色
深度学习可以拿来根据对象以及场景来为照片上色,而且结果很像人类的着色结果。这种解决方案使用了巨大的卷积神经网络和有监督的层来再次创造颜色。
机器翻译
深度学习可以对未经处理的语言序列进行翻译,它促使算法可以学习单词之间的依赖关系,并将其映射到一种新的语言中。大体量的LSTM的RNN网络可以拿来做这些处理。
图像中的对象分类与测试
这些任务必须将图像分成之前我们所了解的某一类型别中。目前这类任务最好的结果是使用超大体量的卷积神经网络推动的。突破性的进展是AlexKrizhevsky等人在ImageNet比赛中使用的AlexNet模型。
自动产生手写体
这些任务是先给定一些手写的文字,然后尝试生成新的类似的手写的结果。首先是人用笔在纸上手写一些文字,然后根据写字的笔迹作为语义来练习模型,并最后学习造成新的内容。
自动玩游戏
这项任务是按照电脑屏幕的图像,来决定怎样玩游戏。这种很难的任务是深度提升模型的探究领域,主要的突破是DeepMind团队的成果。
聊天机器人
一种基于sequencetosequence的建模来创造一个聊天机器人,用以提问这些难题。它是按照长期的实际的会话数据集产生的。
虽然深度学习的探究还存在许多疑问,但它对机器学习领域形成的妨碍是不容忽视的。更加复杂且更注重大的深度模型能深刻阐述大数据里所承载的信息,并对将来和未知事件作更准确的分析。总之,深度学习是一个值得探究的领域,在将来的几年必定会变得的成熟。

转载原创文章请注明,转载自设计培训_平面设计_品牌设计_美工学习_视觉设计_小白UI设计师,原文地址:http://zfbbb.com/?id=6503
